
원하는 것은 뭐든지
99클럽 코테 스터디 15일차 TIL , Prefix and Suffix Search 본문
반응형

문제
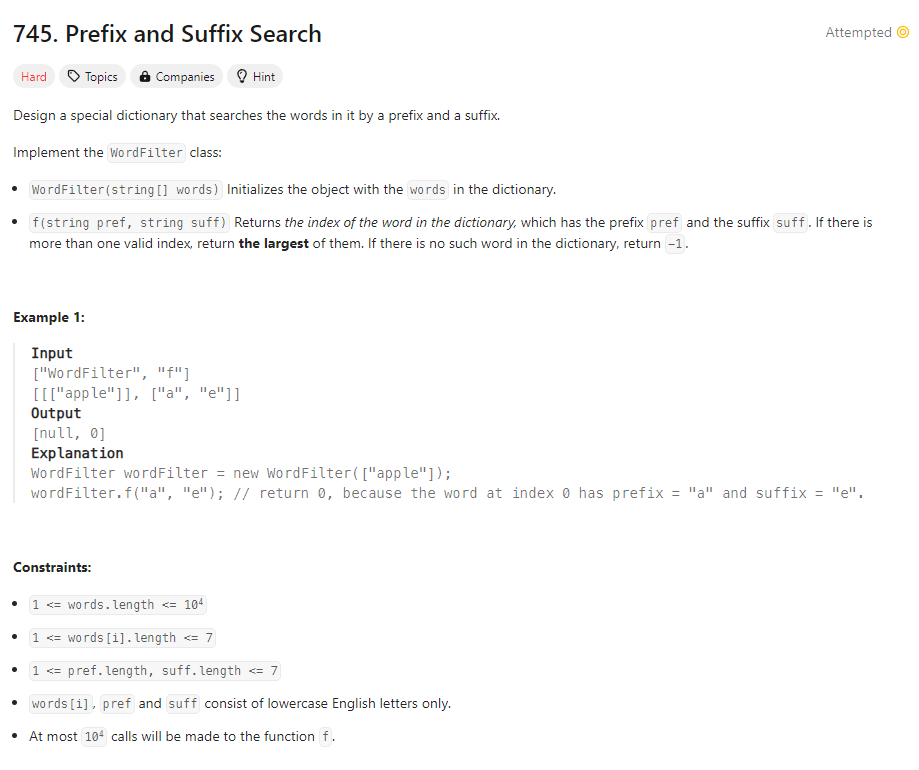
풀이
리트코드 문제는 처음이라 조금 어색했는데 클래스, 메서드까지 주어지는 형식이라 로직만 구현하면 된다.
이번 문제는 결국 해결 못했다.
제출 1 - 오답
class WordFilter {
private String[] words;
public WordFilter(String[] words) {
this.words = words;
}
public int f(String pref, String suff) {
int result = -1;
for(int i=0;i<words.length;i++){
String str = words[i];
if(str.indexOf(pref) == 0 && str.lastIndexOf(suff) == str.length()-suff.length()){
result = i;
}
}
return result;
}
}
단어가 10^4개라 시간초과가 안 날 줄 알았는데 indexOf의 시간을 생각하지 못했다.
확인한 풀이 1
class WordFilter {
private Map<String, Integer> dictionary;
public WordFilter(String[] words) {
dictionary = new HashMap<>(); //HashMap으로 초기화
for(int i=0;i<words.length;i++){
String str = words[i];
for(int j=1;j<=str.length();j++){
for(int k=0;k<str.length();k++){
//들어오는 단어들의 모든 pref, suff 경우들을 Map에 모두 담는다.
dictionary.put(str.substring(0,j) + "-" + str.substring(k), i);
}
}
}
}
public int f(String pref, String suff) {
return dictionary.getOrDefault(pref+ "-" + suff, -1);
}
}
코드로 닿지 못했으나 그나마 생각했던 풀이 방법이었다.
문자열이 10000번이고 단어길이는 길어야 7글자이니까 시간초과는 나지 않는다.
확인한 풀이 2
class WordFilter {
private final String[] words;
public WordFilter(String[] words) {
this.words = words;
}
public int f(String pref, String suff) {
int result = -1;
for(int i=words.length-1;i>=0;i--){
String str = words[i];
if(str.charAt(0) != pref.charAt(0)) continue;
if(str.startsWith(pref) && str.endsWith(suff)){
result = i;
break;
}
}
return result;
}
같은 미들러 분의 풀이를 보고 옮겨 봤다.
적절한 조건문을 사용해서 시간을 단축시킨 로직.
일단 접두사 첫글자가 다르면 통과시키고, 큰 인덱스를 찾아야 하므로 뒤에서부터 탐색하여 접두사, 접미사가 맞는 것을 찾음
확인한 풀이 3
import java.util.*;
public class WordFilter {
private class TrieNode {
// 자식 노드 배열, 소문자로만 되어있기 때문에 사이즈는 26
private final TrieNode[] children = new TrieNode[26];
// 해당 단어(접두사, 접미사) 까지 오는데 있었던 인덱스
private final List<Integer> wordIndices = new ArrayList<>();
}
private final TrieNode prefixRoot = new TrieNode(); // 접두사 트라이의 루트
private final TrieNode suffixRoot = new TrieNode(); // 접미사 트라이의 루트
// 단어의 특정 부분을 트라이에 삽입하는 메서드
private void insert(final String word, final int start, final int end,
final int step, TrieNode root, final int index) {
for (int i = start; i != end; i += step) {
int charIndex = word.charAt(i) - 'a'; // 현재 문자에 대한 인덱스 계산
// 현재 문자에 대한 자식 노드가 없으면 생성
if (root.children[charIndex] == null) {
root.children[charIndex] = new TrieNode();
}
// 현재 노드를 자식 노드로 갱신,
//apple 이라면 a -> p -> p -> l -> e 이런 식으로 연결 됨
root = root.children[charIndex];
// 노드에 단어 인덱스 추가
// 이를 통해서 접두사나 접미사가 몇번째 인덱스에 있는지 알 수 있음
root.wordIndices.add(index);
}
}
// 트라이에서 특정 부분 문자열에 해당하는 인덱스를 검색하는 메서드
private List<Integer> getIndices(final String str, final int start, final int end, final int step, TrieNode root) {
for (int i = start; i != end; i += step) {
//이런식으로 어디까지 갔는지 확인
root = root.children[str.charAt(i) - 'a']; // 현재 문자에 대한 자식 노드로 이동
if (root == null) return Collections.emptyList(); // 자식 노드가 없으면 빈 리스트 반환
}
return root.wordIndices; // 현재 노드의 인덱스 리스트 반환
}
// 생성자: 단어 배열을 이용해 트라이를 초기화
public WordFilter(final String[] words) {
// 중복 단어를 방지하기 위한 Set
final Set<String> processedWords = new HashSet<>();
// 각 단어를 삽입
for (int i = words.length - 1; i >= 0; i--) {
String word = words[i];
if (processedWords.contains(word)) continue; // 이미 처리된 단어는 건너뜀
processedWords.add(word); // 단어 추가
// 접두사와 접미사 트라이에 단어 삽입
//(단어, 시작 인덱스, 끝 인덱스, 반복문 step, 트라이루트, 현재 인덱스)
insert(word, 0, word.length(), 1, prefixRoot, i);
insert(word, word.length() - 1, -1, -1, suffixRoot, i);
}
}
// 주어진 접두사와 접미사로 단어를 찾고 가장 큰 인덱스를 반환하는 메서드
public int f(final String prefix, final String suffix) {
//단어가 어디까지 갔는지 알 수 있도록 가져옴
//(접두사/접미사, 시작 인덱스, 끝 인덱스, 반복문 step, 루트)
List<Integer> prefixIndices = getIndices(prefix, 0, prefix.length(), 1, prefixRoot);
List<Integer> suffixIndices = getIndices(suffix, suffix.length() - 1, -1, -1, suffixRoot);
// 두 리스트를 비교하여 가장 큰 공통 인덱스 찾기
// 큰 인덱스부터 담겨있기 때문에 큰 것부터 비교해가면서 같은 인덱스가 나올 때 까지 반복
int prefixIndex = 0, suffixIndex = 0;
while (prefixIndex < prefixIndices.size() && suffixIndex < suffixIndices.size()) {
int prefixValue = prefixIndices.get(prefixIndex);
int suffixValue = suffixIndices.get(suffixIndex);
if (prefixValue == suffixValue) return suffixValue; // 동일한 인덱스 발견 시 반환
// 두 인덱스 비교 후 더 큰 인덱스를 가진 리스트를 진행
if (suffixValue > prefixValue) {
suffixIndex++;
} else {
prefixIndex++;
}
}
return -1; // 공통 인덱스가 없을 경우 -1 반환
}
}
트라이 구조를 사용한 것, 디버깅을 해보며 이해했음.
이런 경우 아니고서도 사용할 일이 있을 것 같아서 비슷한 문제를 풀어볼 필요성을 느낌
설명은 코드에 해두었음
TIL
- 다른 코드를 확인하고 직접 타이핑 해봄
반응형
'개발 > 문제풀이' 카테고리의 다른 글
| 99클럽 코테 스터디 17일차 TIL , 촌수계산 (0) | 2024.08.08 |
|---|---|
| 99클럽 코테 스터디 16일차 TIL , 모음사전 (0) | 2024.08.07 |
| 99클럽 코테 스터디 14일차 TIL , 숫자 카드 2 (0) | 2024.08.04 |
| 99클럽 코테 스터디 13일차 TIL , 숫자 카드 (0) | 2024.08.04 |
| 99클럽 코테 스터디 12일차 TIL , H-Index (0) | 2024.08.02 |
'개발/문제풀이' Related Articles
more




Comments